A modern Python SDK for PI Web API (open source)
We open-sourced pisharp-piwebapi — an async/sync, fully-typed Python SDK that removes the boilerplate from reading and writing AVEVA PI data over the PI Web API.
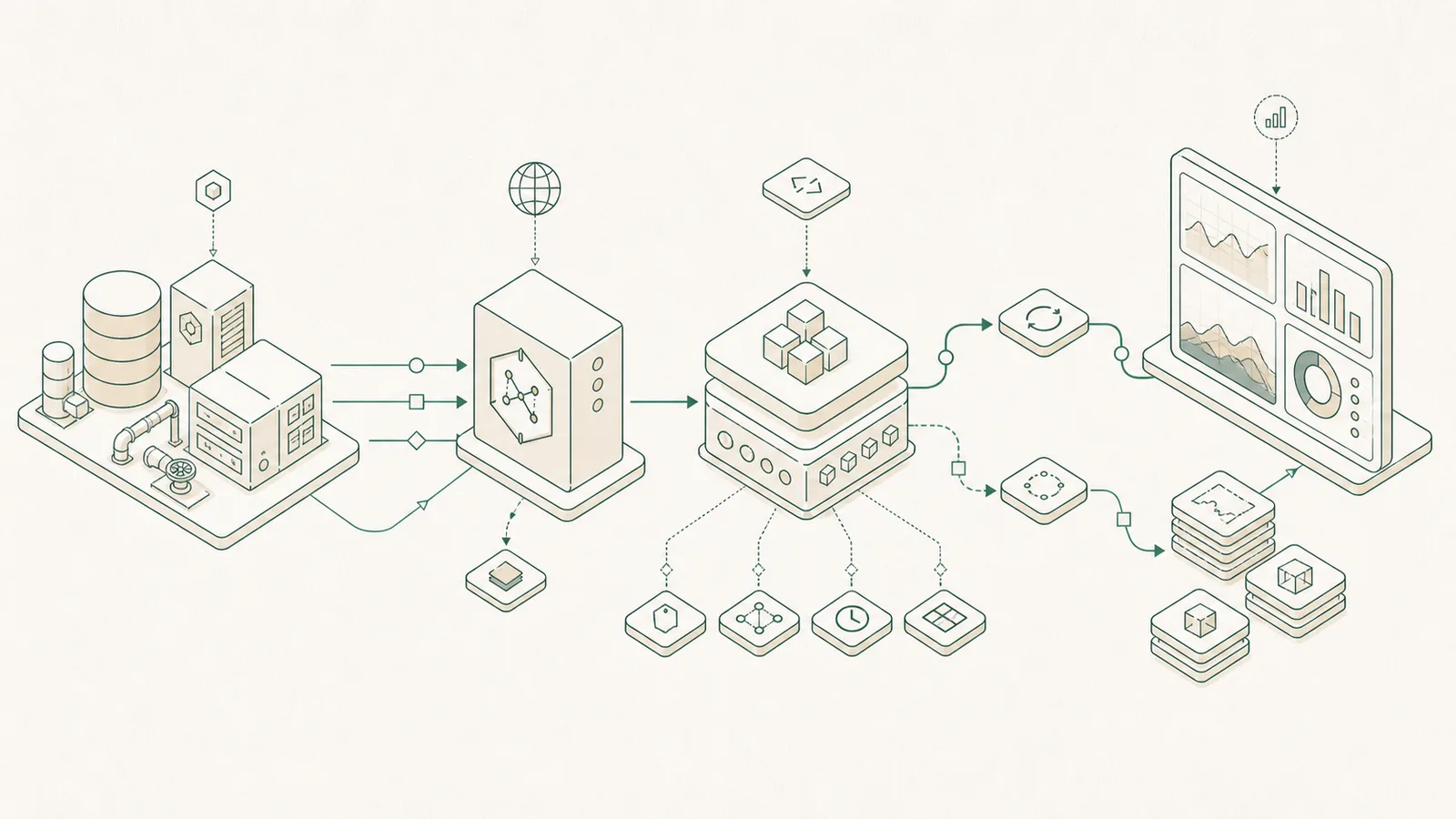
The PI Web API is the most portable way to get AVEVA PI System data into anything that speaks HTTP — but using it raw means hand-writing auth, pagination, batching, and response parsing for every project. We kept rebuilding that plumbing, so we extracted it into an open-source library and put it on PyPI: pisharp-piwebapi. It is Apache-2.0 licensed and maintained as part of the PiSharp developer toolkit.
We built it for PiSharp, our independent developer platform for AVEVA PI System professionals, and extracted the reusable core as open source. It's the same library we reach for whenever PI data needs to move over HTTP.
What problem does it actually remove?
Talking to the PI Web API directly is a REST grind: build the right URL, encode the WebID, page through Links.Next, batch calls so you don't hammer the server, then parse loosely-typed JSON by hand. The SDK collapses that into typed method calls. You ask for a point by path and read its value; the library handles the HTTP, the paging, and the parsing into Pydantic v2 models, so your editor autocompletes the response instead of you guessing at dictionary keys.
How do you read a PI point's value?
Install with pip install pisharp-piwebapi, create a PIWebAPIClient with your PI Web API base URL and credentials, then look up a point and read it. In practice: client.points.get_by_path(r"\\SERVER\sinusoid") returns a typed point, and client.streams.get_value(point.web_id) returns its current value and timestamp. Recorded history over a window is client.streams.get_recorded(web_id, start_time="-1h", end_time="*"), and writing back is client.streams.update_value(web_id, value=42.0). The PI relative-time syntax you already know (-1h, *) passes straight through.
Does it support async for high-volume pulls?
Yes. There are two clients with the same surface: PIWebAPIClient for straightforward scripts, and AsyncPIWebAPIClient for concurrent workloads — used as an async context manager and awaited (await client.streams.get_value(...)). It runs on httpx under the hood and requires Python 3.10+. When you are fanning thousands of tag reads into a warehouse load, the async client lets you do that concurrently instead of one blocking request at a time.
What does it cover beyond reading tags?
- Points & Streams — lookup by path or WebID, read current, recorded, and interpolated values, and write values back.
- Elements & Attributes — browse the PI Asset Framework hierarchy, walk children, and create or delete elements and attributes.
- Event Frames — search, create, acknowledge, and delete, for downtime and batch analysis.
- Servers & Databases — list asset and data servers and browse AF databases and top-level elements.
- Batch requests — bundle many API calls into a single HTTP round-trip.
- Automatic pagination — the client follows Links.Next across all pages so you don't write paging loops.
How does it fit a Power BI or analytics pipeline?
The optional pandas extra (pip install pisharp-piwebapi[pandas]) gives StreamValues.to_dataframe(), turning PI stream values straight into a DataFrame — the natural first step before summarising and shipping into SQL, a cloud lake, or Power BI. For Windows-authenticated estates there is a Kerberos extra (pip install pisharp-piwebapi[kerberos]), plus Basic and client-certificate auth. There is also OpenAPI codegen to generate typed wrappers from your own server's Swagger spec.
Should you use the SDK or roll your own?
If you are doing a one-off proof of concept, raw requests are fine. The moment a pull needs to be dependable, typed, and cheap to maintain for years, the boilerplate — auth, paging, batching, error handling — is exactly the part that rots. That is what the SDK standardises, and the durable pipeline on top of it is the part we build. If your PI data is trapped in the historian, a short discovery call is the fastest way to map what's realistic on your specific deployment.
- 01AVEVA PI System — AVEVA
- 02PiSharp — PI Web API guides & open-source SDK — PiSharp
- Power BI for oil & gas operations in Oman: how operators actually do it
- AVEVA PI System vs open-source historians: which fits your plant?
- Oman's Kafa'a programme: build the factory data layer first
- Oman's industrial AI gap: make PI data shareable first
- AVEVA PI System analytics in Oman: a practical guide
- Getting data out of AVEVA PI: PI Web API vs AF SDK vs Integrators
- How to connect AVEVA PI to Power BI (without the pain)