Getting data out of AVEVA PI: PI Web API vs AF SDK vs Integrators
When you need PI data in another system, you have three realistic routes. Here are the trade-offs between the PI Web API, the AF SDK, and PI Integrators.
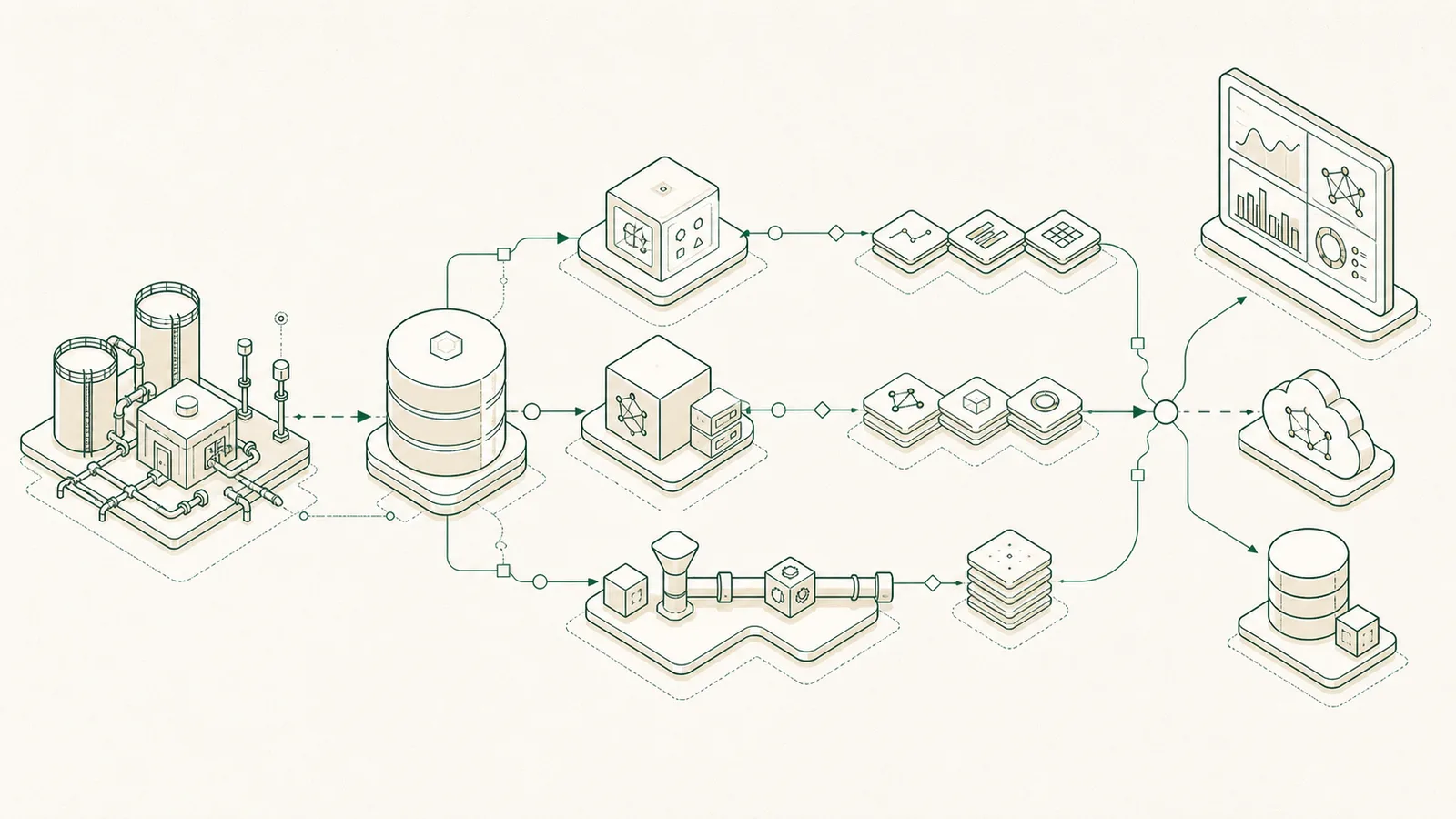
Almost every PI analytics project starts with the same question: how do we get the data out reliably, without destabilising the historian? There are three routes worth knowing, and the right one depends on volume, latency, and who maintains it.
When should you use the PI Web API?
The PI Web API is a RESTful interface over PI Data Archive and AF. It's the most flexible and developer-friendly route: any language that speaks HTTP can read tags, AF attributes, and summaries. It's the right default for custom apps, scheduled pulls into a warehouse, and integrations you control. The cost is that you design the batching, paging, and error handling yourself.
When does the AF SDK make sense?
The .NET AF SDK is the lowest-level, highest-performance option for heavy or latency-sensitive workloads running close to the PI infrastructure. It's powerful but ties you to .NET and to engineers who know PI internals — so it's best when raw throughput matters more than portability.
What about PI Integrators / PI Cloud Connect?
AVEVA's own integrators push PI data to relational or cloud targets with less custom code. They're the cleanest path when your destination is standard (a SQL warehouse, a cloud lake) and you'd rather buy than build the pipe — at the cost of licensing and less control over shaping the data.
So which one should you pick?
- Custom dashboards, chatbots, or warehouse loads you control → PI Web API.
- High-volume, low-latency, on-prem processing → AF SDK.
- Standard cloud/SQL destination, minimal custom code → PI Integrators.
- Unsure → start with the PI Web API; it's the most portable and the easiest to evolve.
Whatever the route, the hard part is rarely the first pull — it's making it dependable, monitored, and cheap to run for years. That's the part we productise.
- 01AVEVA PI System — AVEVA
- Power BI for oil & gas operations in Oman: how operators actually do it
- AVEVA PI System vs open-source historians: which fits your plant?
- Oman's Kafa'a programme: build the factory data layer first
- Oman's industrial AI gap: make PI data shareable first
- A modern Python SDK for PI Web API (open source)
- AVEVA PI System analytics in Oman: a practical guide
- How to connect AVEVA PI to Power BI (without the pain)